At Obin, our core infrastructure relies on the efficient processing of hundreds of thousands of documents through distributed pipelines utilizing Vertex AI. For a company focused on high-scale document intelligence, the reliability and throughput of these pipelines are critical to operational success. However, managing external API constraints at this scale presents a significant engineering challenge, particularly when standard rate-limiting strategies fail to account for the nuances of distributed system behavior -- calls to LLMs are often subject to systematic capacity constraints.
Our initial implementation relied on a traditional Additive Increase, Multiplicative Decrease (AIMD) algorithm—the same mechanism used by TCP for network congestion control. Under this reactive model, the system gradually increases the concurrency limit after successful requests but cuts it in half immediately upon encountering a 429 rate-limit error. In a distributed context, we found this approach insufficient; a single error often triggered a cascade where independent workers retried simultaneously, compounding the overload. This resulted in a "sawtooth" pattern where the system spent more time recovering from crashes and oscillating than performing productive work.
Analysis of our pipeline logs revealed a predictable correlation: latency scaled proportionally with concurrency. As concurrency rose from 10 to 40, latency increased from 15 seconds to a 60-second timeout. This indicated that the API utilized internal queuing, meaning higher concurrency did not improve throughput but merely increased wait times for all requests. Crucially, the API signaled stress through these increased response times well before returning explicit 429 errors, suggesting that latency could serve as a proactive signal for load reduction.
Drawing on research from Vegas-style algorithms and Netflix’s concurrency-limits library, we moved toward a hybrid control strategy. While pure latency-based limiting can be slow to ramp down or blind to failures, a hybrid approach uses latency for proactive management and AIMD as a reactive safety net. The proactive layer monitors response times against a baseline; when latency rises moderately, the system freezes the concurrency limit, and when it rises significantly, it reduces load preemptively before a failure occurs.
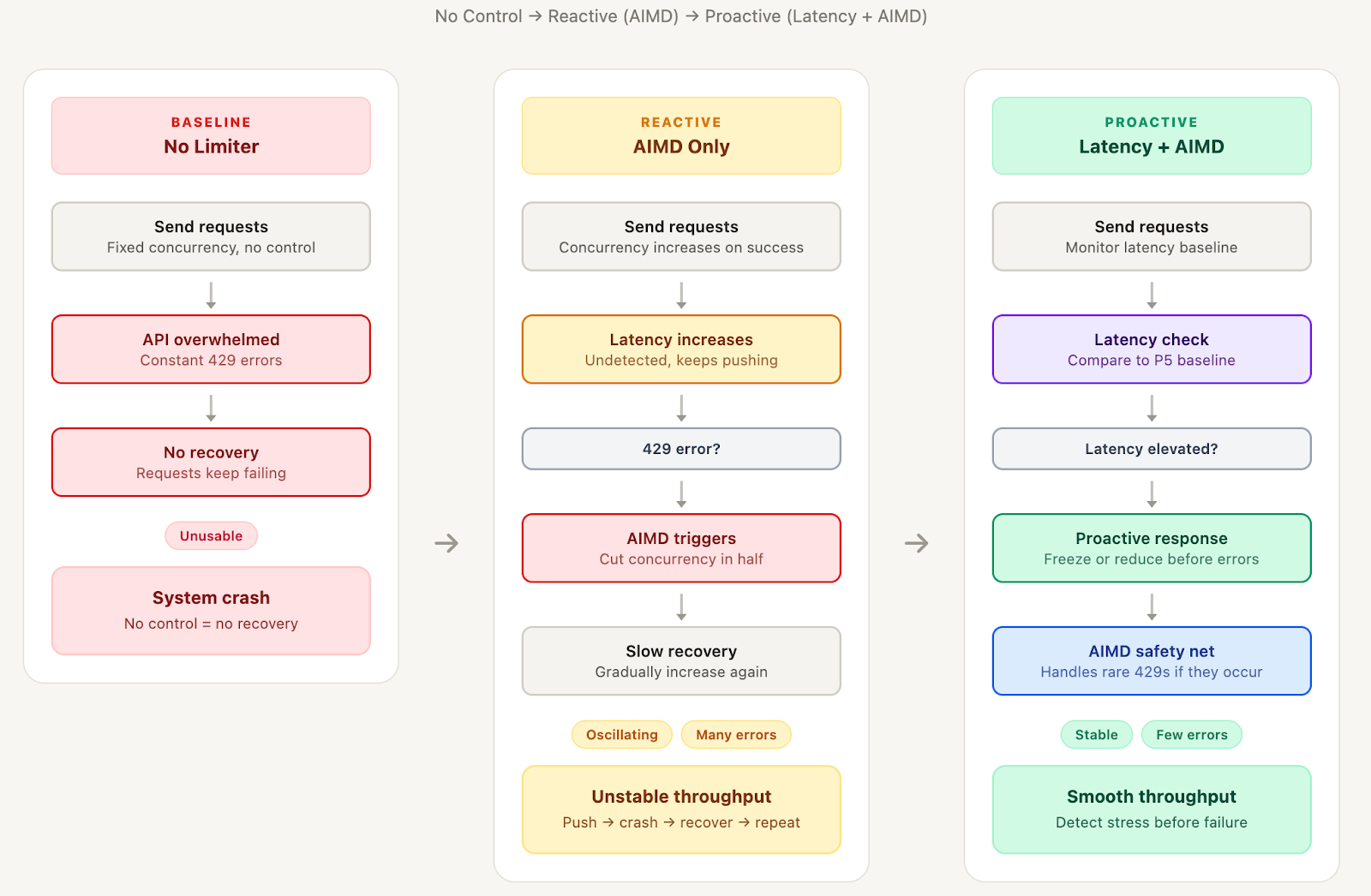
The primary challenge in proactive control is establishing an accurate baseline, as API performance varies based on document complexity and server load. We found that fixed baselines were too rigid and running averages were easily skewed by outliers. Our final implementation utilizes the P5 (5th percentile) of recent latencies to identify what the API achieves when healthy. This approach allows the system to learn workload patterns dynamically and resist the influence of occasional slow responses without requiring hardcoded thresholds.
The shift to a latency-adaptive limiter has delivered a 7x improvement in throughput, with average sustained rates increasing from 2,800 to 22,000 documents per hour. More importantly, the error rate dropped by 98%, with the concurrency limit remaining stable at higher levels rather than crashing to 1.0 during surges. By detecting stress signals before failures cascade, we have moved from a system that oscillates around capacity to one that consistently identifies and maintains it.